“7天医学奇迹” – NHANES研究挑战,Day 5: 数据的魔法时刻!




🚨 “7天医学奇迹” – NHANES研究挑战,Day 5: 数据的魔法时刻!
大家好,我们正处在这场充满挑战的7天医学研究马拉松的中点。今天,我们不仅完成了数据的整理,还制作了一系列图表和图形,为深入分析铺平了道路。
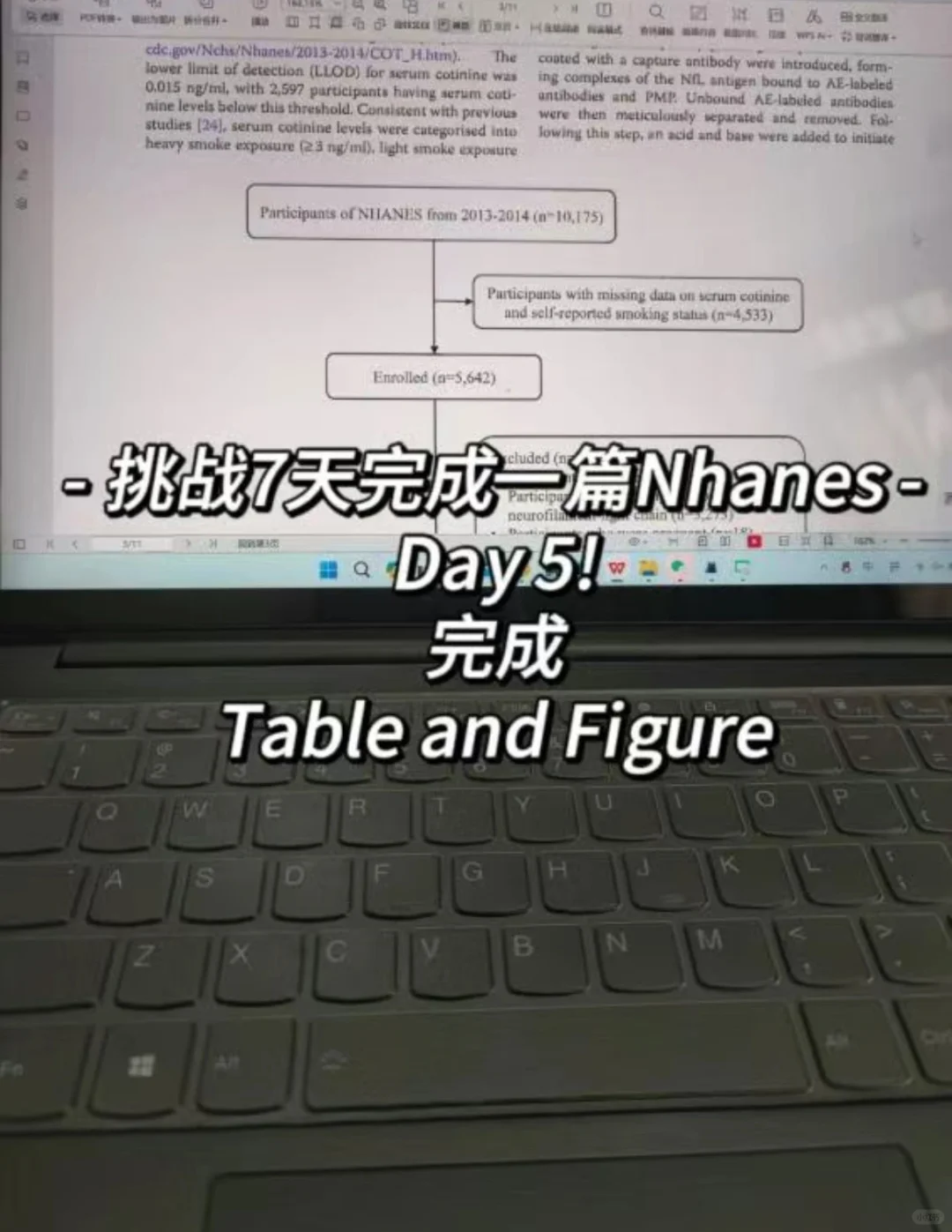
🔎 数据筛选:像侦探一样寻找线索
Figure 1:我们的筛选流程图就像侦探的线索板,展示了如何从2013-2014年的数据中,精心挑选出1900位研究对象。这是我们研究的坚实起点。
📊 基线资料对比:两军对垒,谁主沉浮
Table 1:我们用t-检验和卡方检验这两个统计学利器,揭示了抑郁组与非抑郁组在基线资料上的微妙差异。
🧬 回归分析:解开X与Y之间的秘密
Table 2:从基础模型到综合了人口统计学、疾病和生活方式因素的高级模型,我们一步步深入探索了X与Y之间的复杂关系。
📉 剂量效应关系:寻找X与Y之间的黄金分割点
Figure 2:利用限制性回归样条(RCS)技术,我们像寻宝者一样,探索了X与Y之间的剂量效应关系,寻找那个关键的拐点。
👥 亚组分析:不同群体的独特视角
Table 3:我们对不同群体(性别、年龄等)进行了细致的分析,发现了X与Y关系在不同群体中的多样性,并尝试用文献来解释这些有趣的现象。
🎯 总结与展望:精准选题与数据整理的黄金法则
总结来说,NHANES文章的成功秘诀在于精准的选题和细致的数据整理。我们的耐心和对正确研究方向的坚持,是我们走向成功的坚实基石。今天的任务已经顺利完成,为接下来的研究工作奠定了坚实的基础。
🚀 挑战继续,我们的目标是星辰大海!
我们将继续前进,用科学的方法,探索未知,解答疑惑。加入我们的研究之旅,一起见证这场7天医学研究挑战的最终成果!
💌 互动时间:你最好奇哪个部分的发现?在评论区分享你的想法,让我们一起讨论!