1区6.2分!Charls选题巧思:烹饪燃料暴露与肺功能相关的文章~


一、文章内容解读
1.研究背景
研究主题:本文研究了烹饪燃料暴露与中国成年人慢性肺部疾病(CLD)和肺功能之间的纵向关联。
研究意义:慢性肺部疾病是全球导致死亡和发病率高的原因之一,尤其在低收入和中等收入国家。除了吸烟,烹饪燃料暴露是研究最多的风险因素之一。了解烹饪燃料类型与CLD之间的因果关系对于改善公共卫生具有重要意义。
2.研究方法
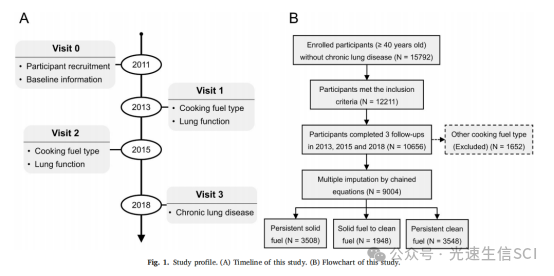
数据来源:数据来自中国健康和退休纵向研究(CHARLS),一个全国代表性的前瞻性队列研究,涉及2011年至2018年的数据。
参与者信息:研究包括了来自中国28个省的9004名40岁及以上的参与者。
指标计算:
CLD识别:基于2018年自我报告的医生诊断。
肺功能评估:通过峰值呼气流速(PEF)评估,分别在2011年、2013年和2015年进行测量。
统计分析和方法:
使用多变量逻辑和线性混合效应重复测量模型来衡量CLD和PEF与烹饪燃料类型的关联。
进行三水平混合效应模型作为敏感性分析。
考虑社区和家庭对数据结构的潜在影响,使用三水平混合效应模型。
对于连续变量和分类变量,分别使用方差分析或Kruskal-Wallis H检验以及卡方检验进行比较。
使用多重插补处理缺失数据。
计算归因病例(AT)和人群可归因分数(PAF)来量化由于使用固体烹饪燃料而导致的CLD负担。
3.研究结果
3.1参与者特征

研究共纳入了9004名参与者,其中3508名持续使用固体燃料,1948名从固体燃料转换到清洁燃料,3548名持续使用清洁燃料。使用清洁燃料的参与者更年轻、不吸烟、居住在城市地区、BMI和腰围较大、肺功能更好、教育水平更高、工作比例较低、健康保险比例较高、接受公共养老金的比例较高、家庭消费水平较高、CLD发病率较低、高血压和糖尿病的患病率较高。这些特征表明,使用清洁燃料的群体在社会经济和健康状况上可能更为优越。

3.2 烹饪燃料类型与CLD的关联
持续使用清洁燃料:与持续使用固体燃料的参与者相比,持续使用清洁燃料的参与者患CLD的风险较低(调整后的比值比[aOR] = 0.73)。这意味着持续使用清洁燃料与CLD风险降低有关。
从固体燃料转换到清洁燃料:那些在研究期间从固体燃料转换到清洁燃料的参与者,其CLD风险也有所降低(aOR = 0.81)。这表明改变烹饪燃料类型可能对降低CLD风险有积极影响。
归因病例(AT)和人群可归因分数(PAF):通过计算,研究估计如果所有参与者在整个调查期间都使用清洁燃料,可以减少4.55%的CLD患者(对于从固体燃料转换到清洁燃料的群体)和9.71%的CLD患者(对于持续使用清洁燃料的群体)。

3.3 烹饪燃料类型与PEF的关联
持续使用清洁燃料:与持续使用固体燃料的参与者相比,持续使用清洁燃料的参与者在PEF水平上显著更高(β = 10.54)。
从固体燃料转换到清洁燃料:在2013年从固体燃料转换到清洁燃料的参与者,其PEF下降的速度较慢(β = 18.00),表明这种转换可能有助于保持肺功能。
时间与烹饪燃料类型的交互作用:研究还发现烹饪燃料类型与时间对PEF有显著的交互作用,这可能意味着随着时间的推移,烹饪燃料类型的改变对肺功能的影响可能会变化。

3.4 敏感性分析
敏感性分析使用三水平混合效应模型进行,结果与主要分析一致,进一步验证了主要分析结果的稳健性。这表明即使在考虑了可能的聚类效应后,使用清洁燃料与降低CLD风险和改善PEF水平之间的关系仍然成立。
4.结论
研究发现:减少固体烹饪燃料的暴露与CLD风险降低和肺功能改善有关。从固体燃料转换到清洁燃料也有益于呼吸健康。
临床意义:改善家庭空气质量有望减少慢性肺部疾病的负担。
二、统计学知识点梳理
多变量逻辑回归模型:用于评估分类结果(如CLD)与多个自变量(如烹饪燃料类型)之间的关联。
线性混合效应重复测量模型:用于评估连续结果(如PEF)在多个时间点的重复测量数据。
三水平混合效应模型:考虑个体、社区和家庭三个层次的数据结构,用于评估烹饪燃料类型与CLD和PEF的关联。
方差分析(ANOVA)和Kruskal-Wallis H检验:分别用于比较连续变量和非正态分布连续变量的组间差异。
卡方检验:用于比较分类变量的组间差异。
多重插补:用于处理缺失数据,通过创建多个完整的数据集来估计参数的不确定性。
归因病例(AT)和人群可归因分数(PAF):用于量化由于特定暴露(如使用固体烹饪燃料)而导致的疾病负担。
三、如何快速开展这类研究
第一步:明确研究主题
确定研究问题,例如烹饪燃料暴露与慢性肺部疾病之间的关系。
第二步:设计研究方案
确定研究设计,如前瞻性队列研究,并定义研究的时间框架和数据收集点。
第三步:参与者选择
确定目标人群,如40岁及以上的中国成年人,并制定纳入和排除标准。
第四步:计算和定义变量
定义主要的暴露变量(烹饪燃料类型)和结果变量(CLD和PEF)。
第五步:数据分析方法
选择合适的统计模型,如多变量逻辑回归和线性混合效应模型,并准备处理缺失数据和控制混杂因素。
第六步:结果解读
解释模型的输出,包括效应大小、置信区间和P值,并进行敏感性分析。
第七步:撰写研究报告
根据研究结果撰写报告,包括研究背景、方法、结果和结论,并讨论研究的临床意义。