100%接收率的GBD数据库挖掘挑战,DAY1!

普通方案去做数据库挖掘,不管是哪个数据库,接收率都偏低,针对这种情况,我优化了数据库挖掘的方案,挑战接收率100%的GBD挖掘的写法(数十位师妹师弟已发表Q1、Q2区Sci论文),作为我们GBD数据库挖掘系列论文的收官之作。
最近在西安从参加一个学术会议
我在”长安”城墙下冲击这份挑战
参加学术会议最大的感受:
大家都在铆足了劲儿的向前冲锋
师弟师妹们是否最近也有paper pressure呢

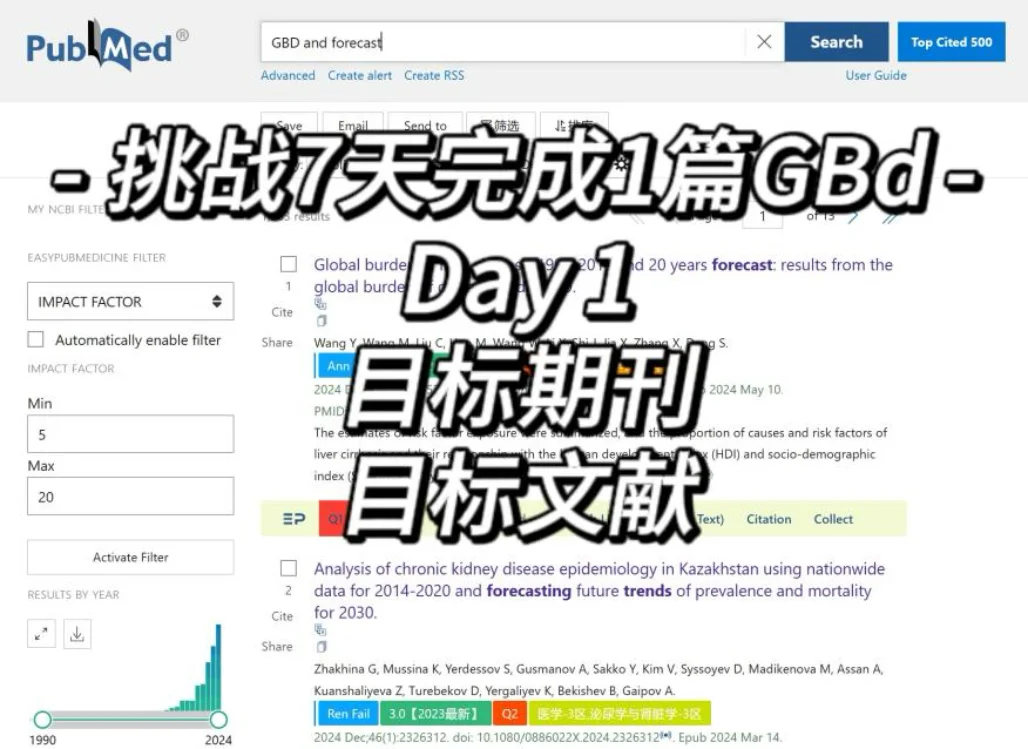
Day1任务:确定目标文献和目标期刊
最近GBD处于数据库挖掘的风口
前面挑战了几期
大家对于这个数据库也比较熟悉了
虽然最近卡了很多的bug
就是在数据下载的过程中排队时间很久
尽管有些问题,但是不得不承认
这是我们发顶刊文章的性价比最高的方法

GBD数据库SCI 主要分成两个方面:描述和分析
描述:描述某一种疾病的时间空间和人群分布
分析:APC、分解分析、ARIMA预测未来等
我们采用100%接收的方案。
“公开数据库是文章黑洞”
因为数据在不断的更新
可以针对研究目的调整疾病/地区/人群等
大家熟悉的META分析本质上也是公开数据库挖掘
Meta发顶刊的一大把
所以,有价值的idea才是最重要的
我们因为基础代码包已经准备好,操作起来也比较的简单
我去检索了GBD and forecast
总共有1,283 results
这确实也从侧面说明了GBD数据库的火爆
我们一定要抓住这波机会
我差不多知道一些常见的疾病肯定已经被写光了
检索后果然不出我所料
那我选了一个小众的疾病
“Global burden of XXXX 1990-2021 and 30 years forecast: results from the GBD 2021.”
经过既往的文献阅读经验来看
最终我选择了经典老牌杂志BMC Public Health作为我的目标期刊
为什么选择这个分不高但是很经典的杂志呢
是被Hylion搞怕了
以前都说什么“发文友好型期刊”
但是。
我们还是要谨慎
选择的目标文献是2024年才发表的文章
欢迎大家关注
冲锋冲锋!